In this post I’ll try to describe a simple solution, that I came up with, to solve the issue of dynamically updating DNS records when the IP addresses of your machines/instances changes frequently.
While Dynamic DNS isn’t a new thing and many services/tools around the internet already provide solutions to this problem (for more than 2 decades), I had a few requirements that ruled out most of them:
I didn’t want to sign up to a new account in one of these external services.
I would prefer to use a domain name under my control.
I don’t trust the machine/instance that executes the update agent, so according to the principle of the least privilege, the client should only able to update one DNS record.
The first and second points rule out the usual DDNS service providers and the third point forbids me from using the Cloudflare API as is (like it is donein other blog posts), since the permissions we are allowed to setup for a new API token aren’t granular enough to only allow access to a single DNS record, at best I would’ve to give access to all records under that domain.
My solution to the problem at hand was to put a worker is front of the API, basically delegating half of the work to this “serverless function”. The flow is the following;
agent gets IP address and timestamp
agent signs the data using a previously known key
agent contacts the worker
worker verifies signature, IP address and timestamp
worker fetches DNS record info of a predefined subdomain
If the IP address is the same, nothing needs to be done
If the IP address is different, worker updates DNS record
worker notifies the agent of the outcome
Nothing too fancy or clever, right? But is works like a charm.
I’ve published my implementation on GitHub with a FOSS license, so anyone can modify and reuse. It doesn’t require any extra dependencies, it consists of only two files and you just need to drop them at the right locations and you’re ready to go. The repository can be found here and the README.md contains the detailed steps to deploy it.
There are other small features that could be implemented, such as using the same worker with several agents that need to update different records, so only one of these “serverless functions” would be required. But these improvements will have wait for another time, for now I just needed something that worked well for this particular case and that could be easily deployed in a short time.
The reaction that followed the announcement on many technology focused forums and communities was mostly negative (example 1, example 2 and example 3), pointing out many problems, mostly with the way it was implemented and with the default settings used by Mozilla.
In this post I will try to summarize the core of whole controversy and list the pros and cons of it.
How does a DNS query work?
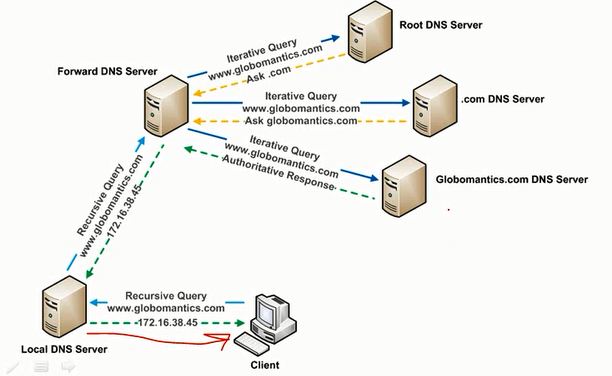
In a very brief and not 100% accurate way, when you try to visit a website such as www.some-example.com, your computer first asks a DNS server (resolver) for the IP address of that website, this server address is usually defined on your system either manually (you set it up) or automatically (when you join a given WiFi network, for example, the network will tell you a server you can use).
That server address generally is set system wide and will be used by all apps. If the server knows the location of the website it will tell you the answer, otherwise it will try to find the location using one of 2 approaches (I will avoid any details here) and come back to you with the result.
You browser will then use this result to fetch the contents of the website. The bellow image describes this flow:
This system is kind of distributed across many entities. Different people across the globe will contact different servers according to their settings and network/location.
DNS over HTTPS
The previously described flow already exists for decades and does not change with DoH, what changes is the way you contact the server in order to ask for the website location and the way this data is transmitted.
While the standard implementation uses UDP and the information travels in cleartext throughout the network (everybody can see it) with DoH this is done as an HTTP request that uses TCP with an encrypted connection, protecting you from malicious actors.
In the end this should be a good thing, but as we will see later on the post things will do south.
Current implementation
A great deal of the discussion this week was sparked by a blog post telling people to turn off Firefox’s DoH, the main complains resolve around not the DoH in itself but the way Mozilla decided to introduce it. Being opt-out and not opt-in, the browser ignoring system configuration and using the servers of a single company by default.
With the current implementation we end up with:
The good
The good part is the obvious reason for using DNS over HTTPS, all your websites queries are encrypted and protected while in transit on the network. It is the extra protection that has been needed for “DNS traffic” for a while.
The bad
The first bad part is that the browser will work differently from the rest of the apps which can cause confusion (why this URL work on the browser and not on my app?), the browser no longer will connect to the same server that was defined for the whole systems
Related to the above problem there is also special network configurations that will stop working such as internal DNS names, rules and filters that are often used on private networks and rely on the internal DNS servers. For these scenarios Mozilla described a series of checks and fallbacks (such as “canary domains”) to accommodate this situation, however they look like fragile hacks.
The ugly
The ugly part is that all DNS traffic from the browser will go to a single entity by default, no matter where you are or which network you are using, which raises privacy concerns and increases the centralization of the system. There is the option of manually setting up a different server however 99% of the users will rely on that single provider.
Conclusion
The overall the intention was good and having encrypted DNS resolution is something that has been required for a very long time but hasn’t become mainstream yet.
The core of the problem with Mozilla’s approach is making it “opt-out”, which means all users will now tell a single “Mozilla partner” the websites they visit by default, without being aware of it.
It will also create some problems to solutions that are deployed network wide and rely on setting certain DNS configurations, since Firefox will not respect them. We can also expect an increased centralization on a system that has been previously working the other way around.
Lets hope that in the future DoH and other encrypted alternatives become standardized so we can continue to use DNS as we always did and don’t have to manage it on every application.
{kind=link}