Since I started using DuckDuckGo in the early 2010s, one of my favorite features that made me stay around to this day was the !bangs.
Essentially, if you want to search on a particular website, you don’t need to open that page before starting to search. With bangs, you just use the appropriate 2 or 3 character code in your search box (browser, home page, etc.), together with your search query, and you are promptly redirected to that website.
Although I am a heavy user of this feature, it always felt wasteful, given we are including an intermediary on a functionality that could easily be done locally.
But you know, convenience and habits are mighty forces.
Anyway, recently I found out that Firefox can do this for us, and even better, you can add “unlimited” custom bangs to your setup. Even after decades, Firefox keeps surprising me occasionally with features that were there right in front of my eyes, but I never noticed them.
Setting up keyword searches in Firefox
So allow me to explain. This wonderful browser empowers the user to create a similar experience to the bangs in two ways:
What is the piece of software (app) you have used continuously for the longest period of time?
This is an interesting question. More than 2 decades have passed since I’ve got my first computer. Throughout all this time my usage of computers evolved dramatically, most of the software I installed at the time no longer exists or is so outdated that there no point in using it.
Even the “type” of software changed, before I didn’t rely on so many web apps and SaaS (Software as a service) products that dominate the market nowadays.
The devices we use to run the software also changed, now it’s common for people to spend more time on certain mobile apps than their desktop counterparts.
In the last 2 decades, not just the user needs changed but also the communication protocols in the internet, the multimedia codecs and the main “algorithms” for certain tasks.
It is true that many things changed, however others haven’t. There are apps that were relevant at the time, that are still in use and I expect that they will still be around in for many years.
I spent some time thinking about my answer to the question, given I have a few strong contenders.
One of them is Firefox. However my usage of the browser was split by periods when I tried other alternatives. I installed it when it was initially launched and I still use it nowadays, but the continuous usage time doesn’t take it to the first place.
I used Windows for 12/13 straight years before switching to Linux, but it is still not enough (I also don’t think operating systems should be taken into account for this question, since for most people the answer would be Windows).
VLC is another contender, but like it happened to Firefox, I started using it early and then kept switching back and forth with other media players throughout the years. The same applies to the “office” suite.
The final answer seems to be Thunderbird. I’ve been using it daily since 2004, which means 16 years and counting. At the time I was fighting the ridiculously small storage limit I had for my “webmail” inbox, so I started using it to download the messages to my computer in order to save space. I still use it today for totally different reasons.
And you, what is the piece of software or app you have continuously used for the longest period of time?
The reaction that followed the announcement on many technology focused forums and communities was mostly negative (example 1, example 2 and example 3), pointing out many problems, mostly with the way it was implemented and with the default settings used by Mozilla.
In this post I will try to summarize the core of whole controversy and list the pros and cons of it.
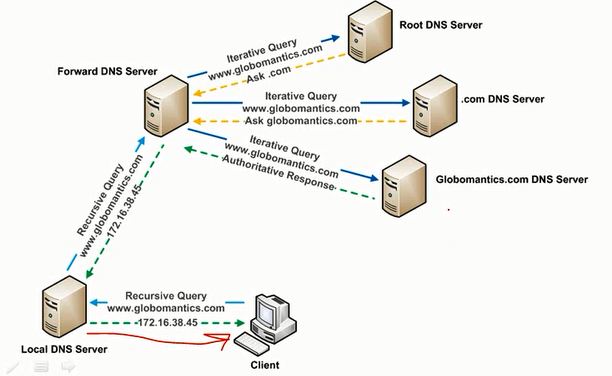
How does a DNS query work?
In a very brief and not 100% accurate way, when you try to visit a website such as www.some-example.com, your computer first asks a DNS server (resolver) for the IP address of that website, this server address is usually defined on your system either manually (you set it up) or automatically (when you join a given WiFi network, for example, the network will tell you a server you can use).
That server address generally is set system wide and will be used by all apps. If the server knows the location of the website it will tell you the answer, otherwise it will try to find the location using one of 2 approaches (I will avoid any details here) and come back to you with the result.
You browser will then use this result to fetch the contents of the website. The bellow image describes this flow:
This system is kind of distributed across many entities. Different people across the globe will contact different servers according to their settings and network/location.
DNS over HTTPS
The previously described flow already exists for decades and does not change with DoH, what changes is the way you contact the server in order to ask for the website location and the way this data is transmitted.
While the standard implementation uses UDP and the information travels in cleartext throughout the network (everybody can see it) with DoH this is done as an HTTP request that uses TCP with an encrypted connection, protecting you from malicious actors.
In the end this should be a good thing, but as we will see later on the post things will do south.
Current implementation
A great deal of the discussion this week was sparked by a blog post telling people to turn off Firefox’s DoH, the main complains resolve around not the DoH in itself but the way Mozilla decided to introduce it. Being opt-out and not opt-in, the browser ignoring system configuration and using the servers of a single company by default.
With the current implementation we end up with:
The good
The good part is the obvious reason for using DNS over HTTPS, all your websites queries are encrypted and protected while in transit on the network. It is the extra protection that has been needed for “DNS traffic” for a while.
The bad
The first bad part is that the browser will work differently from the rest of the apps which can cause confusion (why this URL work on the browser and not on my app?), the browser no longer will connect to the same server that was defined for the whole systems
Related to the above problem there is also special network configurations that will stop working such as internal DNS names, rules and filters that are often used on private networks and rely on the internal DNS servers. For these scenarios Mozilla described a series of checks and fallbacks (such as “canary domains”) to accommodate this situation, however they look like fragile hacks.
The ugly
The ugly part is that all DNS traffic from the browser will go to a single entity by default, no matter where you are or which network you are using, which raises privacy concerns and increases the centralization of the system. There is the option of manually setting up a different server however 99% of the users will rely on that single provider.
Conclusion
The overall the intention was good and having encrypted DNS resolution is something that has been required for a very long time but hasn’t become mainstream yet.
The core of the problem with Mozilla’s approach is making it “opt-out”, which means all users will now tell a single “Mozilla partner” the websites they visit by default, without being aware of it.
It will also create some problems to solutions that are deployed network wide and rely on setting certain DNS configurations, since Firefox will not respect them. We can also expect an increased centralization on a system that has been previously working the other way around.
Lets hope that in the future DoH and other encrypted alternatives become standardized so we can continue to use DNS as we always did and don’t have to manage it on every application.
A few days ago it was announced that next versions of Firefox will have huge improvements on performance and resource usage. This is great because browsers nowadays consume huge amounts of resources, making it harder for people with olders or weaker machines to use the computer without starting to pulling out their hair.
I’m not a huge fan of having lots of opens tabs, but I know many people that like to work this way, having dozens of them open. One question I always ask is how they find the tab they are looking for, when just the favicons are shown on the tabs.
It looks like Firefox makes it easy to handle this situation without any extra extension, just select the search bar in any tab (Ctrl+l) and then type “% <search query>” to search on the opens tabs.
Firefox has been my browser of choice for quite some time now. However recent decisions made by Mozilla are increasing my desire to change soon. They added “ads” on the “new tab page”, changed the UI to just look like chrome, decided to include DRM directly into the browser (more on that), etc. The last one was to include Pocket, a proprietary service, directly into the open-source browser.
While this service might be useful for many users, other people do not like/use it. This kind of functionality should be relegated to pluggable extensions, one of the features that in its early days gave notoriety to Firefox. So a browser that was supposed to be light, open-source and extensible is slowly starting to drift apart from its initial strengths. This post describes in a short way what seems to be happening.
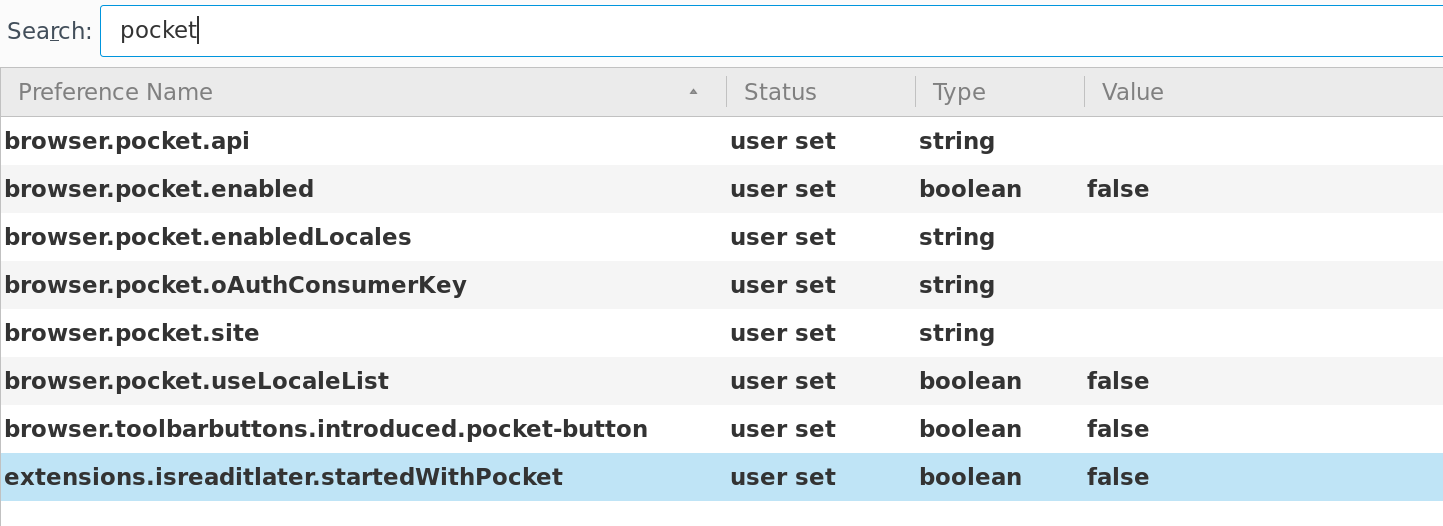
Somebody yesterday wrote a rant about it with some valid points and concerns. So here’s how I disabled pockets in my browser:
Write “about:config” in the address bar.
Click “I will be careful, I promise“.
Search for “pocket“.
Modify it like is shown in the picture bellow.
Restart the browser.
Small extra: if you, like me, don’t like the tab style that just looks like chrome, you can switch to the development theme by changing the line “browser.devedition.theme.enabled” to true. Want the dark theme? Change the line “devtools.theme” to “dark“.
Now lets hope that Mozilla puts an end to this series of bad decisions in a near future.
Note: In Firefox v40 the development theme is no longer available (or at least accessible), so to use it you will need an extension.
Some time ago, while cleaning stuff in my computer, I decided to switch my browser to Opera and delete the version of Firefox that I was using at the time. While doing that and removing all the Firefox folders that are left behind, I accidentally erased all my bookmarks and I didn’t had them synced with some on-line service. Well that wasn’t good, I had references stored there that I wanted to keep.
When trying to recover the file ‘places.sqlite’ I found an bookmark backup generated by Firefox. When I opened the file I found that it was a mess, basically it was bunch of big JSON objects stored in one line containing lots of garbage (I only needed the urls).
I kept that file until today, when I finally decided that I would put those bookmarks again in my browser. As Opera doesn’t import this kind of files, I made a little python script that extracts the names and urls of the backup and generates a single file that opera can import, while keeping the folder structure.
Well, it worked, so I tought it might be usefull to someone else and pushed it to github. If any of you ever have the same problem give it a shoot and use this “quick fix”. You can find it here with some instructions on how to use it. If you find any problem, use the comments and github issues.
{kind=link}