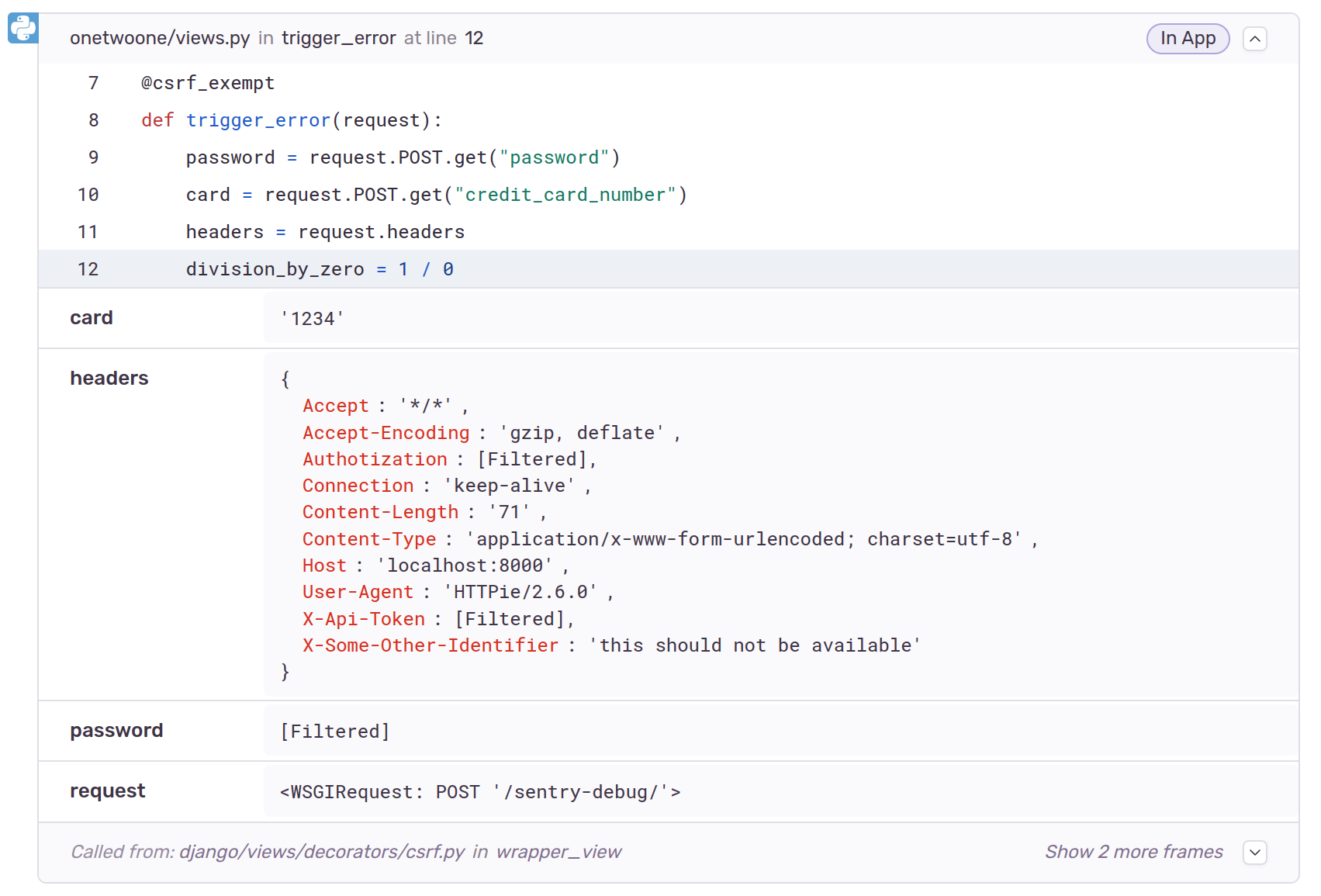
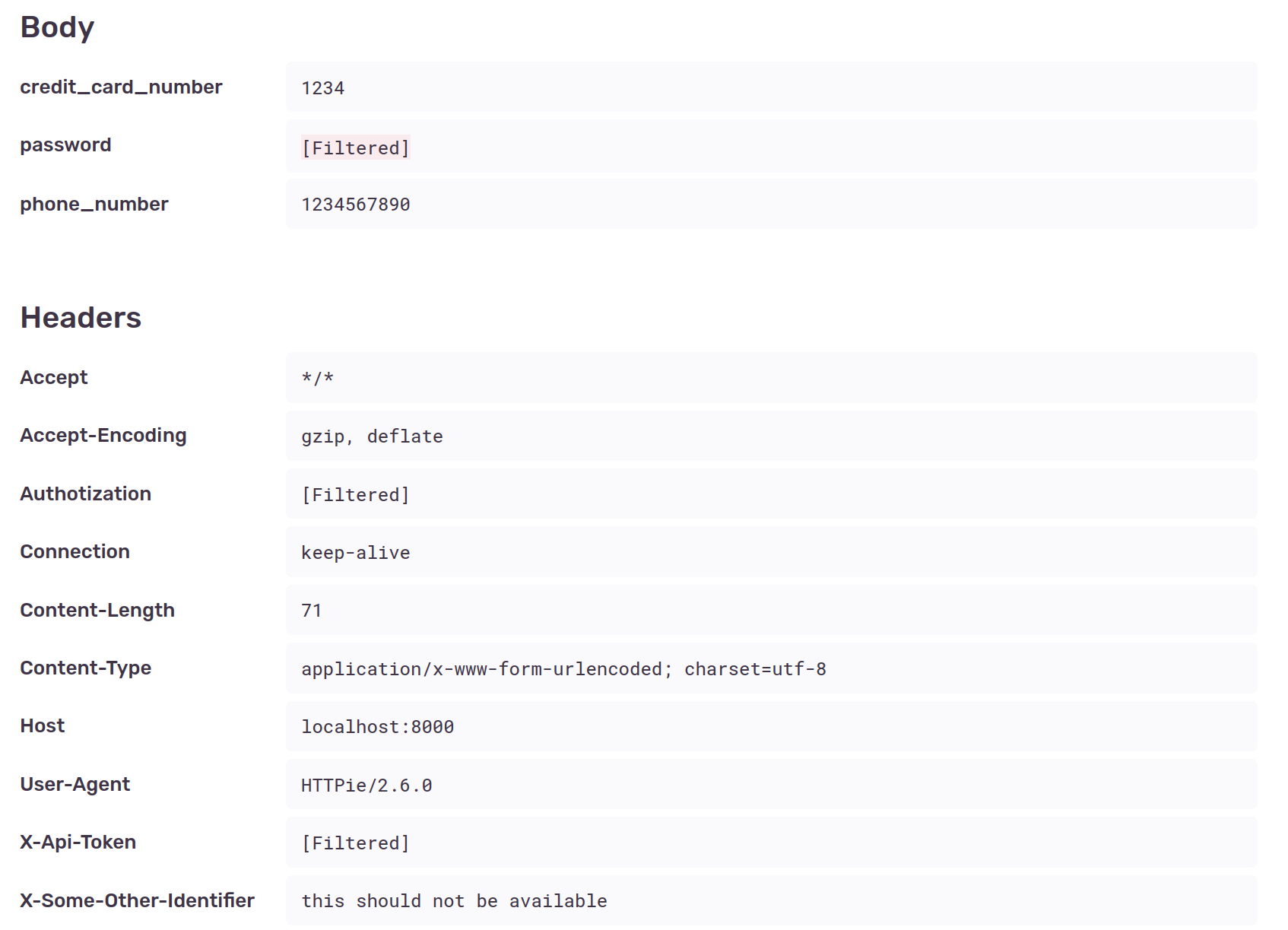
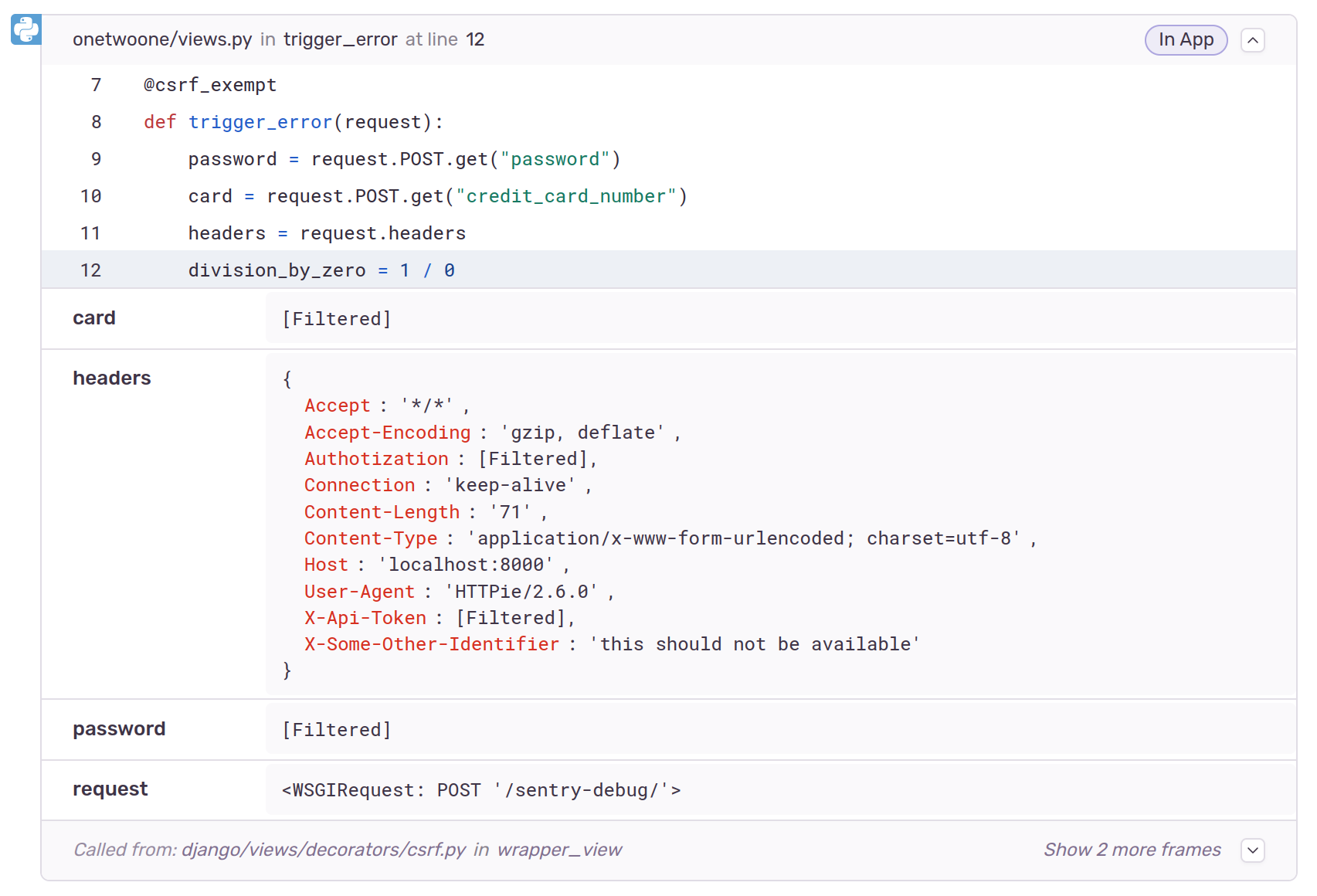
Ten years ago, after it became clear to almost everyone that all our online activity was being tracked and stored, I wrote a blog post about simple steps a person could take to improve their privacy online.
Essentially, it contains a few recommendations that everyone could follow to reduce their fingerprint without much effort. It wasn’t meant to be exhaustive, and it wasn’t meant to make you invisible online. If your personal situation needs more, you have a lot more ground to cover, which was totally out of the scope of that post.
The target audience was the average Joe, that doesn’t like to be spied on. Specially by commercial companies that just want to show you ads, sell you stuff or use your habits against you.
Many things have changed in the last 10 years, while others remained the same. With this in mind, I think it is time for an update to my suggestions, keeping in mind that no specialized knowledge should be required and the maximum amount of effort should not surpass 30 minutes.
1. Pick an ethical browser
For regular users on any computer or operating system, the main window to the outside world is the browser. Nowadays, this app is of the utmost importance.
My initial suggestion remains valid these days, you should install and use Firefox.
There are other browsers that could also do the trick, such as Brave or Safari, but my preference still goes to Mozilla’s browser.
No matter your choice, you should avoid Chrome and Edge. If you want a more detailed comparison, you can check this website.
Expected effort: 5 minutes
2. Install important extensions
Unfortunately, the default configuration of a good browser is not enough, even considering it already includes many protections enabled from the start.
For a minimal setup, I consider 2 extensions indispensable:
These will ensure that most spyware, included in a huge number of websites, isn’t loaded and does not leak your private information to third-parties. They will also block ads and other junk that make the web slow and waste your bandwidth.
Expected effort: 2 minutes
3. Opt out of any data collection
This topic is specially problematic for Microsoft Windows users. However, it is becoming an increase prevalent practice in all software vendors.
They will tell you they are collecting anonymous data to improve their products and services, while often the data is not that anonymous and/or the purposes are far wider than the ones they make you believe initially.
Nowadays, Windows is an enormous data collection machine, so to minimize the damage, you should disable as much of this as possible. If this is your operating system, you can find a step-by-step tutorial of the main things to disable here (note: you should evaluate if the last 3 steps make sense for your case).
If you use a different operating system, you should do a small research about what data the vendor collects.
The next action is to do the same on your browser. In this case, in Firefox you should paste about:preferences#privacy in the URL bar, look for Firefox Data Collection and Use and then disable all options.
Expected effort: 2–8 minutes
4. Use a better DNS resolver
This suggestion is a bit more technical, but important enough that I decided to include it in this guide that only covers the basics.
With the new configuration that we set up on points 2 and 3, in theory, we are well protected against these forms of tracking. However, there are 2 big holes:
- Are you sure the operating system settings are being respected?
- Trackers on the browser are being blocked, but what about the other installed applications? Are they spying on you?
To address the 2 points above, you can change your default DNS server to one that blocks any queries to sites tracking your activity. Two examples are Mullvad DNS and Next DNS, but there are others.
Changing your DNS server can also help you block tracking on other devices you have less control, such as your phone or TV.
The links contain detailed guides on how to proceed.
Expected effort: 4–10 minutes
5. Segregate your activity
This step is more related to your behavior and browsing habits than to any tools that you need to install and configure.
The goal here is to clean any data websites leave behind to track you across visits and websites through time.
You should configure your browser to delete all cookies and website related data at the end of each session, and by this, I mean when you close your browser.
In Firefox, you should again to about:preferences#privacy search for “Cookies and Site Data” and check the option: “Delete cookies and site data when Firefox is closed“.
Sometimes this is impractical because it will force you to login into websites and apps all the time. A good compromise is to use “Multi-Account Containers“, they allow you to segregate your activity into multiple isolated containers, so you can limit any tracking capabilities.
Expected effort: 3 minutes
6. Prefer privacy preserving tools and services
Most online services that common folk use, go to huge lengths to track your activities. For most of them, this is their business model.
Luckily, there are drop-in replacements for common tools that will provide you with similar or better service:
The above are just a few examples, these choices will depend on your own needs. At first, you might find them strange, but experience tells me that soon enough you will get used to them and discover they are superior in many ways.
Expected effort: 3–5 minutes
7. Adopt better habits
I’m already a few minutes over budget, but hey, privacy is hard to achieve nowadays.
For this last point, the lesson is that you must be careful with the information you share and make use of GDPR to control when someone is overstepping.
Here are a few tips, just for you to get an idea:
- Don’t provide your personal data just because they ask (input random data if you think it will not be necessary).
- Always reject cookies and disable data collection when websites show those annoying pop-ups. Look for the “reject all” button, they usually hide it.
- Even if websites don’t prompt you about privacy settings, go to your account preferences and disable all data collection.
- Use fake profiles / identities.
- When too much information is needed, and you don’t see the point, search for other alternatives.
The main message is: Be cautious and strict with all the information you share online.
Concluding
If you followed up to this point, you already made some good progress. However, this is the bare minimum and I only covered what to do on your personal computer, even though some of these suggestions will also work on your other devices (phone, tablet, etc.).
I avoided suggesting tools, services and practices that would imply monetary costs for the reader, but depending on your needs they might be necessary.
Nowadays, it is very hard not to be followed around by a “thousand companies and other entities”, specially when we carry a tracking device in our pockets, attached to our wrists, or move around inside one of them.
In case you want to dig deeper, there are a many sources online with more detailed guides on how to go a few steps further. As an example, you can check “Privacy Guides“.
Now, to end my post with a question (so I could also learn something new), what would you recommend differently? Would you add, remove or replace any of these suggestions? Don’t forget about the 30-minute rule.